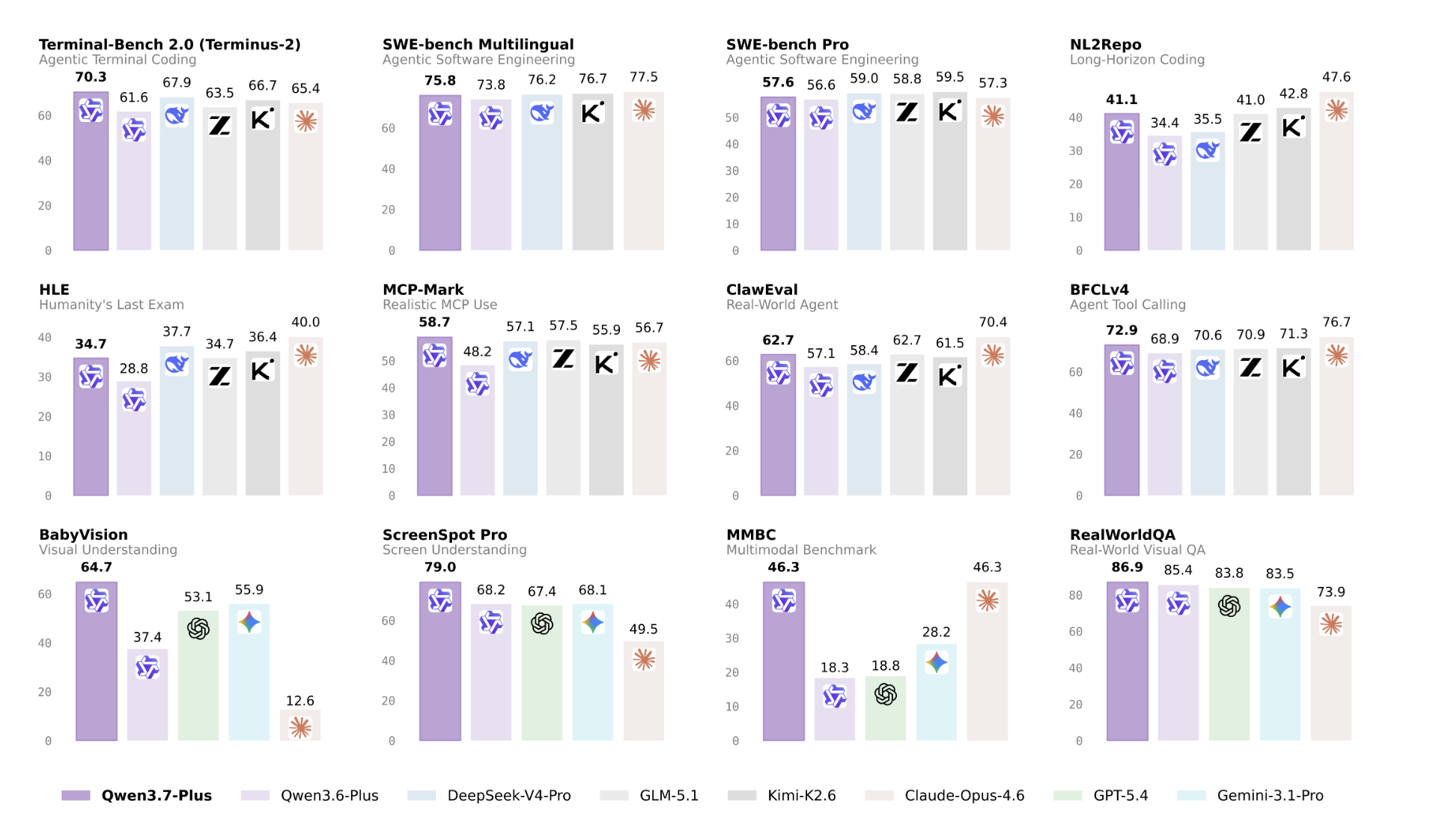
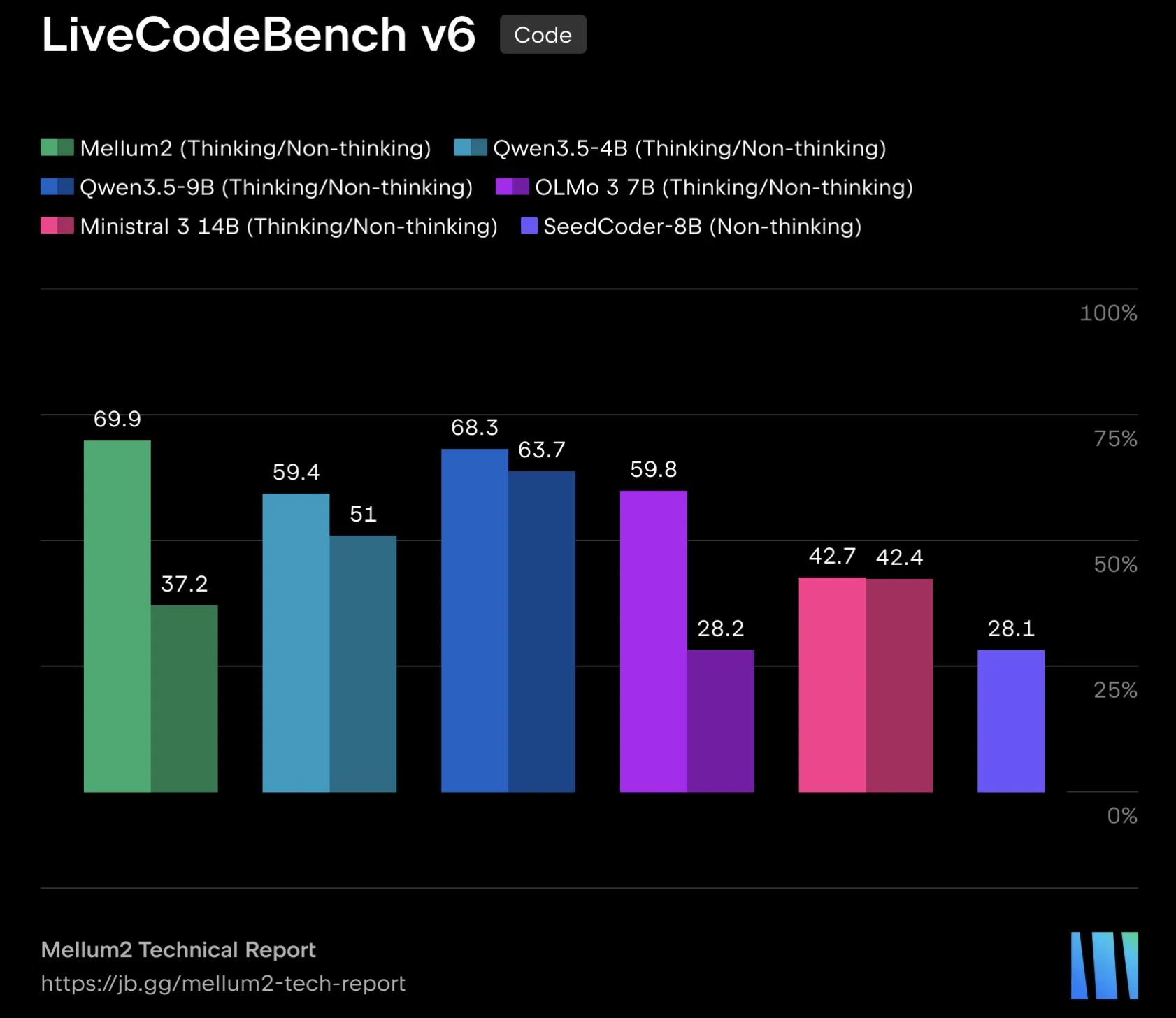
Trending News:Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian PlatformJetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI PipelinesHow to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.ampMiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic CodingMeet Memory OS: A 6-Layer Open-Source Memory Stack Built on Top of Hermes AgentHow we used Gemini to build Google I/O 2026Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction BranchAn Implementation of the Microsoft Agent Governance Toolkit for Safe AI Agent Tool Use with Policies, Approvals, Audit Logs, and Risk ControlsA Coding Implementation on Loguru for Designing Robust, Structured, Concurrent, and Production-Ready Python Logging PipelinesTrajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput GainBuild Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task PlanningBest Text-to-Speech TTS Models in 2026: A Benchmark-Based ComparisonGenesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model EvaluationHermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4How to Use AgentTrove: Streaming 1.7M Agentic Traces and Building a Clean ShareGPT SFT Dataset in PythonNVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1BStepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search WorkflowsCheck out real-life AI prototypes from the Futures Lab.Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven CommunicationHexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model WeightsHow to Design an End-to-End Ansible Automation Lab with Playbooks, Inventories, Roles, Vault, Dynamic Inventory, and Custom ModulesLiquid AI Releases LFM2.5-8B-A1B: An On-Device MoE Model With 8.3B Total and 1.5B Active ParametersPerplexity AI Open-Sources Unigram Tokenizer That Achieves 5x Lower p50 Latency Than Hugging Face tokenizers CrateA Coding Guide to Implement a pgvector-Powered Semantic, Hybrid, Sparse, and Quantized Vector Search SystemSakana AI Proposes DiffusionBlocks: a Block-wise Training Framework That Converts Residual Networks into Independently Trainable Denoising ModulesNVIDIA Releases Polar, a Token-Faithful Rollout Framework for GRPO Training Across Codex, Claude Code, and Qwen CodeMeet EAGLE 3.1: The Speculative Decoding Algorithm That Fixes Attention Drift in LLM InferenceMEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM ParametersDesign a High-Precision Retrieve-and-Rerank Pipeline with ZeroEntropy Zerank-2 RerankerStability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and EditingMeet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabsDesign a Complete Multimodal RLVR Pipeline with Open-MM-RL, Vision-Language Prompting, Reward Scoring, and GRPO ExportTogether AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM ServingStep by Step Guide to Build and Compare FedAvg and FedProx Federated Learning on Non-IID CIFAR-10 with NVIDIA FLAREBest Authentication Platforms for AI Agents and MCP Servers in 2026WorkOS Releases auth.md: An Open Agent Registration Protocol Built on OAuth StandardsBuild a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and ExperimentsStepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic ComprehensionMicrosoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% on Odysseys, Up from Base GPT-5.4’s 33.5%NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta RuleTencent Open-Sources TencentDB Agent Memory: A 4-Tier Local Memory Pipeline for AI AgentsBuild a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session MemoryNous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight ModificationPerplexity Open-Sources Bumblebee: A Read-Only Supply-Chain Scanner for Developer EndpointsA Step-by-Step Coding Tutorial to Implement GBrain: The Self-Wiring Memory Layer Built by Y Combinator’s Garry Tan for AI AgentsCatch up on the Dialogues stage at Google I/O 2026.Microsoft Releases Fara1.5: A Family of Browser Computer-Use Agents (4B/9B/27B) That Outperform OpenAI Operator and Gemini 2.5 Computer Use on Online-Mind2WebBuild Recurrent-Depth Transformers with OpenMythos for MLA, GQA, Sparse MoE, and Loop-Scaled ReasoningHow CopilotKit Is Redefining the Agentic AI Stack in 2026Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context WindowCohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUsOne Model, Three Modalities: ByteDance Releases Lance for Image and Video Understanding, Generation, and EditingWhat is a Forward Deployed Engineer: The AI Role OpenAI, Anthropic, and Google Are Hiring in 2026Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant AlgorithmWe’re announcing new community investments in Missouri.100 things we announced at I/O 2026NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8BAlibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second LatencyGoogle Introduces Gemini 3.5 Flash at I/O 2026: A Faster and Cheaper Model for AI Agents and CodingUpstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?Google Launches Antigravity 2.0 at I/O 2026: A Standalone Agent-First Platform with CLI, SDK, Managed Execution, and Enterprise SupportBest Enterprise Level Agentic AI Platforms for 2026How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI APIMeet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory UtilityStochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token HorizonA Coding Implementation to Compress and Benchmark Instruction-Tuned LLMs with FP8, GPTQ, and SmoothQuant Quantization using llmcompressorVercel Labs Introduces Zero, a Systems Programming Language Designed So AI Agents Can Read, Repair, and Ship Native ProgramsA Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box ModelsNous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long ContextMeet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in ProductionNVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPUHow to Build Repository-Level Code Intelligence with Repowise Using Graph Analysis, Dead-Code Detection, Decisions, and AI ContextHow to Build an MCP Style Routed AI Agent System with Dynamic Tool Exposure Planning, Execution, and Context InjectionZyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x SpeedupBest AI Agents for Software Development Ranked: A Benchmark-Driven Look at the Current FieldSupertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression TagsHow to Build a Django-Unfold Admin Dashboard with Custom Models, Filters, Actions, and KPIsPoetiq’s Meta-System Automatically Builds a Model-Agnostic Harness That Improved Every LLM Tested on LiveCodeBench Pro Without Fine-TuningA Coding Implementation to Master GPU Computing with CuPy, Custom CUDA Kernels, Streams, Sparse Matrices, and ProfilingNous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter ModelsHow to Build a Dynamic Zero-Trust Network Simulation with Graph-Based Micro-Segmentation, Adaptive Policy Engine, and Insider Threat DetectionEnterprise AI Governance in 2026: Why the Tools Employees Use Are Ahead of the Policies That Cover ThemFastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its SizeMira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI CollaborationGoogle DeepMind Introduces an AI-Enabled Mouse Pointer Powered by Gemini That Captures Visual and Semantic Context Around the CursorBuild a Hybrid-Memory Autonomous Agent with Modular Architecture and Tool Dispatch Using OpenAIMeet AntAngelMed: A 103B-Parameter Open-Source Medical Language Model Built on a 1/32 Activation-Ratio MoE ArchitectureTilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in MuonA Coding Implementation to Portfolio Optimization with skfolio for Building Testing, Tuning, and Comparing Modern Investment StrategiesOpenAI Introduces Daybreak: A Cybersecurity Initiative That Puts Codex Security at the Center of Vulnerability Detection and Patch ValidationSakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMsA Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM ApplicationsThe new AI-powered Google Finance is expanding to Europe.Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading SystemsOpenClaw vs Hermes Agent: Why Nous Research’s Self-Improving Agent Now Leads OpenRouter’s Global RankingsNVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTXA Coding Implementation to Recover Hidden Malware IOCs with FLARE-FLOSS Beyond Classic Strings AnalysisNVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing9 Best AI Tools for Spec-Driven Development in 2026: Kiro, BMAD, GSD, and More Compare
Trending News:Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian PlatformJetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI PipelinesHow to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.ampMiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic CodingMeet Memory OS: A 6-Layer Open-Source Memory Stack Built on Top of Hermes AgentHow we used Gemini to build Google I/O 2026Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction BranchAn Implementation of the Microsoft Agent Governance Toolkit for Safe AI Agent Tool Use with Policies, Approvals, Audit Logs, and Risk ControlsA Coding Implementation on Loguru for Designing Robust, Structured, Concurrent, and Production-Ready Python Logging PipelinesTrajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput GainBuild Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task PlanningBest Text-to-Speech TTS Models in 2026: A Benchmark-Based ComparisonGenesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model EvaluationHermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4How to Use AgentTrove: Streaming 1.7M Agentic Traces and Building a Clean ShareGPT SFT Dataset in PythonNVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1BStepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search WorkflowsCheck out real-life AI prototypes from the Futures Lab.Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven CommunicationHexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model WeightsHow to Design an End-to-End Ansible Automation Lab with Playbooks, Inventories, Roles, Vault, Dynamic Inventory, and Custom ModulesLiquid AI Releases LFM2.5-8B-A1B: An On-Device MoE Model With 8.3B Total and 1.5B Active ParametersPerplexity AI Open-Sources Unigram Tokenizer That Achieves 5x Lower p50 Latency Than Hugging Face tokenizers CrateA Coding Guide to Implement a pgvector-Powered Semantic, Hybrid, Sparse, and Quantized Vector Search SystemSakana AI Proposes DiffusionBlocks: a Block-wise Training Framework That Converts Residual Networks into Independently Trainable Denoising ModulesNVIDIA Releases Polar, a Token-Faithful Rollout Framework for GRPO Training Across Codex, Claude Code, and Qwen CodeMeet EAGLE 3.1: The Speculative Decoding Algorithm That Fixes Attention Drift in LLM InferenceMEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM ParametersDesign a High-Precision Retrieve-and-Rerank Pipeline with ZeroEntropy Zerank-2 RerankerStability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and EditingMeet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabsDesign a Complete Multimodal RLVR Pipeline with Open-MM-RL, Vision-Language Prompting, Reward Scoring, and GRPO ExportTogether AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM ServingStep by Step Guide to Build and Compare FedAvg and FedProx Federated Learning on Non-IID CIFAR-10 with NVIDIA FLAREBest Authentication Platforms for AI Agents and MCP Servers in 2026WorkOS Releases auth.md: An Open Agent Registration Protocol Built on OAuth StandardsBuild a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and ExperimentsStepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic ComprehensionMicrosoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% on Odysseys, Up from Base GPT-5.4’s 33.5%NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta RuleTencent Open-Sources TencentDB Agent Memory: A 4-Tier Local Memory Pipeline for AI AgentsBuild a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session MemoryNous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight ModificationPerplexity Open-Sources Bumblebee: A Read-Only Supply-Chain Scanner for Developer EndpointsA Step-by-Step Coding Tutorial to Implement GBrain: The Self-Wiring Memory Layer Built by Y Combinator’s Garry Tan for AI AgentsCatch up on the Dialogues stage at Google I/O 2026.Microsoft Releases Fara1.5: A Family of Browser Computer-Use Agents (4B/9B/27B) That Outperform OpenAI Operator and Gemini 2.5 Computer Use on Online-Mind2WebBuild Recurrent-Depth Transformers with OpenMythos for MLA, GQA, Sparse MoE, and Loop-Scaled ReasoningHow CopilotKit Is Redefining the Agentic AI Stack in 2026Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context WindowCohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUsOne Model, Three Modalities: ByteDance Releases Lance for Image and Video Understanding, Generation, and EditingWhat is a Forward Deployed Engineer: The AI Role OpenAI, Anthropic, and Google Are Hiring in 2026Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant AlgorithmWe’re announcing new community investments in Missouri.100 things we announced at I/O 2026NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8BAlibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second LatencyGoogle Introduces Gemini 3.5 Flash at I/O 2026: A Faster and Cheaper Model for AI Agents and CodingUpstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?Google Launches Antigravity 2.0 at I/O 2026: A Standalone Agent-First Platform with CLI, SDK, Managed Execution, and Enterprise SupportBest Enterprise Level Agentic AI Platforms for 2026How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI APIMeet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory UtilityStochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token HorizonA Coding Implementation to Compress and Benchmark Instruction-Tuned LLMs with FP8, GPTQ, and SmoothQuant Quantization using llmcompressorVercel Labs Introduces Zero, a Systems Programming Language Designed So AI Agents Can Read, Repair, and Ship Native ProgramsA Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box ModelsNous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long ContextMeet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in ProductionNVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPUHow to Build Repository-Level Code Intelligence with Repowise Using Graph Analysis, Dead-Code Detection, Decisions, and AI ContextHow to Build an MCP Style Routed AI Agent System with Dynamic Tool Exposure Planning, Execution, and Context InjectionZyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x SpeedupBest AI Agents for Software Development Ranked: A Benchmark-Driven Look at the Current FieldSupertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression TagsHow to Build a Django-Unfold Admin Dashboard with Custom Models, Filters, Actions, and KPIsPoetiq’s Meta-System Automatically Builds a Model-Agnostic Harness That Improved Every LLM Tested on LiveCodeBench Pro Without Fine-TuningA Coding Implementation to Master GPU Computing with CuPy, Custom CUDA Kernels, Streams, Sparse Matrices, and ProfilingNous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter ModelsHow to Build a Dynamic Zero-Trust Network Simulation with Graph-Based Micro-Segmentation, Adaptive Policy Engine, and Insider Threat DetectionEnterprise AI Governance in 2026: Why the Tools Employees Use Are Ahead of the Policies That Cover ThemFastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its SizeMira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI CollaborationGoogle DeepMind Introduces an AI-Enabled Mouse Pointer Powered by Gemini That Captures Visual and Semantic Context Around the CursorBuild a Hybrid-Memory Autonomous Agent with Modular Architecture and Tool Dispatch Using OpenAIMeet AntAngelMed: A 103B-Parameter Open-Source Medical Language Model Built on a 1/32 Activation-Ratio MoE ArchitectureTilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in MuonA Coding Implementation to Portfolio Optimization with skfolio for Building Testing, Tuning, and Comparing Modern Investment StrategiesOpenAI Introduces Daybreak: A Cybersecurity Initiative That Puts Codex Security at the Center of Vulnerability Detection and Patch ValidationSakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMsA Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM ApplicationsThe new AI-powered Google Finance is expanding to Europe.Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading SystemsOpenClaw vs Hermes Agent: Why Nous Research’s Self-Improving Agent Now Leads OpenRouter’s Global RankingsNVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTXA Coding Implementation to Recover Hidden Malware IOCs with FLARE-FLOSS Beyond Classic Strings AnalysisNVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing9 Best AI Tools for Spec-Driven Development in 2026: Kiro, BMAD, GSD, and More Compare
Meet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in Production
Meet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in Production
Running AI agents in a local script is straightforward. Running them reliably in production across teams, across restarts, with isolated environments per context is a different problem entirely. BerriAI, the company behind the LiteLLM AI Gateway, is now open-sourcing a purpose-built answer to that problem: the LiteLLM Agent Platform. The platform is described as a simple, self-hosted infrastructure platform for running multiple agents in production.
What Problem Does it Solve?
It helps to understand what happens when you try to scale agents beyond a single process. Agents are stateful: they carry session history, tool call results, and intermediate reasoning across turns. If the container running your agent crashes, restarts, or gets replaced during a deployment, that session state is gone unless something is explicitly managing it. At the same time, different teams often need different runtime environments, different tools, different secrets, different access scopes which means you cannot throw all agents into one shared container.
The platform manages two things: per-team and per-context sandboxes, and session continuity across pod restarts and upgrades. These two capabilities are the core infrastructure primitives the platform provides.
Architecture and Technical Stack
The platform is a standalone Next.js dashboard for LiteLLM v2 managed agents, covering sessions chat, agent CRUD, and live status. The codebase is primarily TypeScript (92.8%), with Shell scripts for provisioning, a Dockerfile for containerization, and CSS for the dashboard UI.
The architecture separates concerns cleanly. A web process runs on port 3000 and serves the Next.js dashboard. A worker process handles async agent tasks. Postgres is used as the persistent backing store, and a schema migration runs as an init container on startup — so the database is always in the correct state before the application boots.
For the sandbox layer — the isolated runtime environment where agents actually execute — sandboxes run on Kubernetes via the kubernetes-sigs/agent-sandbox CRD. Local development uses kind. If you are not already familiar with it: kind (Kubernetes in Docker) lets you spin up a full Kubernetes cluster locally using Docker containers as nodes, without needing a cloud provider. The agent-sandbox CRD (Custom Resource Definition) is a Kubernetes extension from kubernetes-sigs that the platform installs to manage the lifecycle of individual sandbox environments.
The platform also includes a harness system under harnesses/opencode, which contains the configuration for running coding agents — such as Claude Code or OpenAI Codex — inside isolated sandboxes with a vault proxy for credential management. BerriAI team also maintains a separate litellm-agent-runtime repository, described as a coding-agent runtime that runs inside per-session VMs provisioned by a LiteLLM proxy, generic by design, with customization happening via harness configuration or a hydrate payload.
One practical detail worth noting is how environment variables are handled across sandbox containers. Anything in .env prefixed with CONTAINER_ENV_ is injected into every sandbox container with the prefix stripped — for example, CONTAINER_ENV_GITHUB_TOKEN=ghp_... means the container sees GITHUB_TOKEN=ghp_... This gives teams a clean way to pass secrets into sandboxed agent sessions without modifying container images.
https://github.com/BerriAI/litellm-agent-platform
Getting Started
The prerequisites for local development are Docker Desktop, kind, kubectl, helm, and a LiteLLM gateway. No cloud credentials are required to get started locally. The quickstart is two commands:
bin/kind-up.sh is idempotent — it provisions a kind cluster named agent-sbx, installs the agent-sandbox controller, and loads the harness image. docker compose up boots Postgres, runs the schema migration, and starts the web process on port 3000 along with the worker.
For production deployment, the recommended path is AWS EKS for the sandbox cluster and Render for the web and worker processes. bin/eks-up.sh provisions the EKS cluster, and a Render Blueprint provides a one-click deployment option.
Relationship to the LiteLLM Gateway
The Agent Platform is a layer on top of the existing LiteLLM ecosystem, not a replacement for it. LiteLLM’s core is a Python SDK and Proxy Server — an AI Gateway — that calls 100+ LLM APIs in OpenAI format, with cost tracking, guardrails, load balancing, and logging, supporting providers including Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, SageMaker, HuggingFace, vLLM, and NVIDIA NIM. The Agent Platform consumes a running LiteLLM gateway as a dependency and builds agent orchestration and session management infrastructure on top of it. Model routing, cost tracking, and rate limiting remain in the gateway layer. Sandbox isolation, session continuity, and the management dashboard are handled by the Agent Platform.
Marktechpost’s Visual Explainer
LiteLLM Agent Platform
Self-Hosted Agent Infrastructure Guide
Alpha
Overview
Concepts
Architecture
Prerequisites
Quickstart
Production
01 / 06
What is LiteLLM Agent Platform?
BerriAI open-sourced this platform on May 8, 2026. It is a self-hosted infrastructure layer for running multiple AI agents in production, built on top of the LiteLLM AI Gateway.
Self-Hosted
Runs entirely on your own infrastructure. No data leaves your environment. Suited for regulated industries and teams with data residency requirements.
Multi-Agent
Designed to run multiple agents in parallel, with full isolation between teams and contexts using per-session sandboxes.
Session Continuity
Agent sessions persist across pod restarts and upgrades, so stateful work is not lost when containers are replaced.
Open Source (MIT)
Fully open source under the MIT license. Repo: github.com/BerriAI/litellm-agent-platform. File issues and contribute directly.
Prerequisite Knowledge
This guide assumes familiarity with Docker, basic command-line usage, and a general understanding of what an AI agent is (a model that calls tools and runs multi-step tasks). Kubernetes experience helps but is not required to follow along.
02 / 06
Key Concepts to Know First
Before running the platform, understand these four building blocks. They appear throughout the setup and configuration.
A
LiteLLM Gateway
The underlying AI Gateway that the Agent Platform depends on. It routes requests to 100+ LLM providers (OpenAI, Anthropic, Bedrock, VertexAI, etc.) using a unified OpenAI-format API. The Agent Platform does not include the gateway, you must have one running separately and point the platform at it.
B
Sandbox
An isolated container environment where a single agent session executes. Each sandbox is independent, meaning one agent cannot access the filesystem, secrets, or state of another. Sandboxes are provisioned and torn down per session using the kubernetes-sigs/agent-sandbox CRD (Custom Resource Definition).
C
Harness
A configuration layer that defines how a specific type of coding agent (such as Claude Code or OpenAI Codex) runs inside a sandbox. The platform ships with an opencode harness under harnesses/opencode/. The harness image is loaded into the kind cluster during setup.
D
CRD (Custom Resource Definition)
A Kubernetes extension that lets you define new resource types. The platform uses the kubernetes-sigs/agent-sandbox CRD to teach your Kubernetes cluster how to manage agent sandboxes as first-class resources, the same way it manages pods or deployments.
03 / 06
How the Platform Is Structured
The platform has four main components. Understanding how they connect helps when debugging or deploying to production.
Component
What It Does
Tech
web (:3000)
Next.js dashboard. Provides the UI for sessions chat, agent CRUD operations, and live status monitoring.
Next.js, TypeScript
worker
Background process that handles async agent tasks, decoupled from the web server.
TypeScript
postgres
Persistent backing store for session state, agent configs, and metadata. Schema migration runs automatically as an init container on startup.
PostgreSQL
sandbox cluster
Kubernetes cluster where individual agent sandboxes run, managed via the agent-sandbox CRD controller. Locally: kind. In production: AWS EKS.
Kubernetes (kind / EKS)
Separation of Concerns
The LiteLLM gateway handles model routing, cost tracking, rate limiting, and guardrails. The Agent Platform handles sandbox lifecycle, session management, and the management dashboard. They run as separate services and the Agent Platform consumes the gateway as a dependency.
04 / 06
Prerequisites Before You Start
Install and verify these tools before running any setup commands. The quickstart will not work without all five.
1
Docker Desktop
Required to build and run containers, and to power kind (which runs Kubernetes nodes as Docker containers). Download from docker.com/products/docker-desktop. Verify with:
docker --version
2
kind (Kubernetes in Docker)
Used to provision a local Kubernetes cluster for running sandboxes. Install via Homebrew on macOS (brew install kind) or from kind.sigs.k8s.io. Verify with:
kind --version
3
kubectl
The Kubernetes command-line tool. Used by the setup scripts to interact with the kind cluster. Install from kubernetes.io/docs/tasks/tools. Verify with:
kubectl version --client
4
helm
The Kubernetes package manager. Used to install the agent-sandbox controller into the kind cluster. Install from helm.sh/docs/intro/install. Verify with:
helm version
5
A Running LiteLLM Gateway
The Agent Platform requires a LiteLLM gateway URL to route model calls. If you do not have one running, start with the official LiteLLM quickstart at docs.litellm.ai. You will point the Agent Platform at this URL during configuration.
05 / 06
Local Quickstart
Clone the repo and run two commands to get the full platform running locally. No cloud credentials needed for local development.
1
Clone the repository
Pull the repo from GitHub:
git clone https://github.com/BerriAI/litellm-agent-platform
cd litellm-agent-platform
2
Configure your .env file
Copy the example env file and fill in your LiteLLM gateway URL and any secrets:
cp .env.example .env
# Edit .env and set your LITELLM_GATEWAY_URL and other required values
3
Provision the local kind cluster
This script is idempotent, meaning safe to run multiple times. It provisions a kind cluster named agent-sbx, installs the agent-sandbox controller via helm, and loads the harness image:
bin/kind-up.sh
4
Start all services
Boots Postgres, runs the schema migration as an init container, and starts the web server on port 3000 and the worker process:
docker compose up
5
Open the dashboard
Navigate to http://localhost:3000 in your browser. You should see the LiteLLM Agent Platform dashboard with options to create agents, open sessions, and monitor live status.
Passing Secrets into Sandboxes
Any variable in .env prefixed with CONTAINER_ENV_ is automatically injected into every sandbox container with the prefix stripped. Example: CONTAINER_ENV_GITHUB_TOKEN=ghp_… means the sandbox sees GITHUB_TOKEN=ghp_… This is the correct way to pass credentials into agent sessions.
06 / 06
Production Deployment
The recommended production setup separates the sandbox cluster (AWS EKS) from the web and worker processes (Render). The repo ships scripts and a Blueprint for both.
1
Provision the EKS sandbox cluster
The bin/eks-up.sh script provisions an AWS EKS cluster configured to run agent sandboxes. This replaces kind as the sandbox backend. Requires AWS credentials in your environment:
bin/eks-up.sh
2
Deploy web and worker to Render
The repo includes a Render Blueprint under deploy/render/ that deploys the web and worker services to Render with one click. See deploy/render/README.md for the Blueprint URL and required environment variables.
3
Use the Developer API directly (optional)
You can interact with the platform programmatically via its REST API using curl or any HTTP client. The full API reference covering how to create an agent, open a session, send a message, and read the reply is at src/server/DEVELOPER.md in the repo.
# Example: create an agent session via curl
curl -X POST http://localhost:3000/api/sessions
-H "Content-Type: application/json"
-d '{"agent_id": "your-agent-id"}'
Architecture Summary for Production
AWS EKS runs the sandbox cluster where agent sessions execute in isolation. Render hosts the Next.js web dashboard and the async worker. Postgres (managed or self-hosted) persists session state. The LiteLLM gateway runs separately and handles all model API routing. These four components communicate over the network and can be scaled independently.
Platform is currently in alpha public preview. File issues at github.com/BerriAI/litellm-agent-platform. Architecture details at docs/k8s-backend.md in the repo.
1 / 6
Published by Marktechpost | AI/ML News and Research for Developers and Engineers
Key Takeaways
BerriAI open-sourced LiteLLM Agent Platform, a self-hosted infrastructure layer for running multiple AI agents in production with per-team sandbox isolation and session continuity across pod restarts.
Sandboxes run on Kubernetes via the kubernetes-sigs/agent-sandbox CRD — locally with kind, in production with AWS EKS — no cloud credentials needed to get started.
The platform sits on top of the existing LiteLLM Gateway, which handles model routing, cost tracking, and rate limiting across 100+ LLM providers in OpenAI format.
The quickstart is two commands: bin/kind-up.sh provisions the kind cluster and installs the sandbox controller; docker compose up boots Postgres, web (:3000), and worker.
Released under MIT license and currently in alpha public preview