Trending News:Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian PlatformJetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI PipelinesHow to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.ampMiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic CodingMeet Memory OS: A 6-Layer Open-Source Memory Stack Built on Top of Hermes AgentHow we used Gemini to build Google I/O 2026Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction BranchAn Implementation of the Microsoft Agent Governance Toolkit for Safe AI Agent Tool Use with Policies, Approvals, Audit Logs, and Risk ControlsA Coding Implementation on Loguru for Designing Robust, Structured, Concurrent, and Production-Ready Python Logging PipelinesTrajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput GainBuild Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task PlanningBest Text-to-Speech TTS Models in 2026: A Benchmark-Based ComparisonGenesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model EvaluationHermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4How to Use AgentTrove: Streaming 1.7M Agentic Traces and Building a Clean ShareGPT SFT Dataset in PythonNVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1BStepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search WorkflowsCheck out real-life AI prototypes from the Futures Lab.Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven CommunicationHexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model WeightsHow to Design an End-to-End Ansible Automation Lab with Playbooks, Inventories, Roles, Vault, Dynamic Inventory, and Custom ModulesLiquid AI Releases LFM2.5-8B-A1B: An On-Device MoE Model With 8.3B Total and 1.5B Active ParametersPerplexity AI Open-Sources Unigram Tokenizer That Achieves 5x Lower p50 Latency Than Hugging Face tokenizers CrateA Coding Guide to Implement a pgvector-Powered Semantic, Hybrid, Sparse, and Quantized Vector Search SystemSakana AI Proposes DiffusionBlocks: a Block-wise Training Framework That Converts Residual Networks into Independently Trainable Denoising ModulesNVIDIA Releases Polar, a Token-Faithful Rollout Framework for GRPO Training Across Codex, Claude Code, and Qwen CodeMeet EAGLE 3.1: The Speculative Decoding Algorithm That Fixes Attention Drift in LLM InferenceMEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM ParametersDesign a High-Precision Retrieve-and-Rerank Pipeline with ZeroEntropy Zerank-2 RerankerStability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and EditingMeet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabsDesign a Complete Multimodal RLVR Pipeline with Open-MM-RL, Vision-Language Prompting, Reward Scoring, and GRPO ExportTogether AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM ServingStep by Step Guide to Build and Compare FedAvg and FedProx Federated Learning on Non-IID CIFAR-10 with NVIDIA FLAREBest Authentication Platforms for AI Agents and MCP Servers in 2026WorkOS Releases auth.md: An Open Agent Registration Protocol Built on OAuth StandardsBuild a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and ExperimentsStepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic ComprehensionMicrosoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% on Odysseys, Up from Base GPT-5.4’s 33.5%NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta RuleTencent Open-Sources TencentDB Agent Memory: A 4-Tier Local Memory Pipeline for AI AgentsBuild a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session MemoryNous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight ModificationPerplexity Open-Sources Bumblebee: A Read-Only Supply-Chain Scanner for Developer EndpointsA Step-by-Step Coding Tutorial to Implement GBrain: The Self-Wiring Memory Layer Built by Y Combinator’s Garry Tan for AI AgentsCatch up on the Dialogues stage at Google I/O 2026.Microsoft Releases Fara1.5: A Family of Browser Computer-Use Agents (4B/9B/27B) That Outperform OpenAI Operator and Gemini 2.5 Computer Use on Online-Mind2WebBuild Recurrent-Depth Transformers with OpenMythos for MLA, GQA, Sparse MoE, and Loop-Scaled ReasoningHow CopilotKit Is Redefining the Agentic AI Stack in 2026Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context WindowCohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUsOne Model, Three Modalities: ByteDance Releases Lance for Image and Video Understanding, Generation, and EditingWhat is a Forward Deployed Engineer: The AI Role OpenAI, Anthropic, and Google Are Hiring in 2026Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant AlgorithmWe’re announcing new community investments in Missouri.100 things we announced at I/O 2026NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8BAlibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second LatencyGoogle Introduces Gemini 3.5 Flash at I/O 2026: A Faster and Cheaper Model for AI Agents and CodingUpstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?Google Launches Antigravity 2.0 at I/O 2026: A Standalone Agent-First Platform with CLI, SDK, Managed Execution, and Enterprise SupportBest Enterprise Level Agentic AI Platforms for 2026How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI APIMeet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory UtilityStochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token HorizonA Coding Implementation to Compress and Benchmark Instruction-Tuned LLMs with FP8, GPTQ, and SmoothQuant Quantization using llmcompressorVercel Labs Introduces Zero, a Systems Programming Language Designed So AI Agents Can Read, Repair, and Ship Native ProgramsA Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box ModelsNous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long ContextMeet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in ProductionNVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPUHow to Build Repository-Level Code Intelligence with Repowise Using Graph Analysis, Dead-Code Detection, Decisions, and AI ContextHow to Build an MCP Style Routed AI Agent System with Dynamic Tool Exposure Planning, Execution, and Context InjectionZyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x SpeedupBest AI Agents for Software Development Ranked: A Benchmark-Driven Look at the Current FieldSupertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression TagsHow to Build a Django-Unfold Admin Dashboard with Custom Models, Filters, Actions, and KPIsPoetiq’s Meta-System Automatically Builds a Model-Agnostic Harness That Improved Every LLM Tested on LiveCodeBench Pro Without Fine-TuningA Coding Implementation to Master GPU Computing with CuPy, Custom CUDA Kernels, Streams, Sparse Matrices, and ProfilingNous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter ModelsHow to Build a Dynamic Zero-Trust Network Simulation with Graph-Based Micro-Segmentation, Adaptive Policy Engine, and Insider Threat DetectionEnterprise AI Governance in 2026: Why the Tools Employees Use Are Ahead of the Policies That Cover ThemFastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its SizeMira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI CollaborationGoogle DeepMind Introduces an AI-Enabled Mouse Pointer Powered by Gemini That Captures Visual and Semantic Context Around the CursorBuild a Hybrid-Memory Autonomous Agent with Modular Architecture and Tool Dispatch Using OpenAIMeet AntAngelMed: A 103B-Parameter Open-Source Medical Language Model Built on a 1/32 Activation-Ratio MoE ArchitectureTilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in MuonA Coding Implementation to Portfolio Optimization with skfolio for Building Testing, Tuning, and Comparing Modern Investment StrategiesOpenAI Introduces Daybreak: A Cybersecurity Initiative That Puts Codex Security at the Center of Vulnerability Detection and Patch ValidationSakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMsA Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM ApplicationsThe new AI-powered Google Finance is expanding to Europe.Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading SystemsOpenClaw vs Hermes Agent: Why Nous Research’s Self-Improving Agent Now Leads OpenRouter’s Global RankingsNVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTXA Coding Implementation to Recover Hidden Malware IOCs with FLARE-FLOSS Beyond Classic Strings AnalysisNVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing9 Best AI Tools for Spec-Driven Development in 2026: Kiro, BMAD, GSD, and More Compare
Trending News:Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian PlatformJetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI PipelinesHow to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.ampMiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic CodingMeet Memory OS: A 6-Layer Open-Source Memory Stack Built on Top of Hermes AgentHow we used Gemini to build Google I/O 2026Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction BranchAn Implementation of the Microsoft Agent Governance Toolkit for Safe AI Agent Tool Use with Policies, Approvals, Audit Logs, and Risk ControlsA Coding Implementation on Loguru for Designing Robust, Structured, Concurrent, and Production-Ready Python Logging PipelinesTrajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput GainBuild Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task PlanningBest Text-to-Speech TTS Models in 2026: A Benchmark-Based ComparisonGenesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model EvaluationHermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4How to Use AgentTrove: Streaming 1.7M Agentic Traces and Building a Clean ShareGPT SFT Dataset in PythonNVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1BStepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search WorkflowsCheck out real-life AI prototypes from the Futures Lab.Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven CommunicationHexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model WeightsHow to Design an End-to-End Ansible Automation Lab with Playbooks, Inventories, Roles, Vault, Dynamic Inventory, and Custom ModulesLiquid AI Releases LFM2.5-8B-A1B: An On-Device MoE Model With 8.3B Total and 1.5B Active ParametersPerplexity AI Open-Sources Unigram Tokenizer That Achieves 5x Lower p50 Latency Than Hugging Face tokenizers CrateA Coding Guide to Implement a pgvector-Powered Semantic, Hybrid, Sparse, and Quantized Vector Search SystemSakana AI Proposes DiffusionBlocks: a Block-wise Training Framework That Converts Residual Networks into Independently Trainable Denoising ModulesNVIDIA Releases Polar, a Token-Faithful Rollout Framework for GRPO Training Across Codex, Claude Code, and Qwen CodeMeet EAGLE 3.1: The Speculative Decoding Algorithm That Fixes Attention Drift in LLM InferenceMEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM ParametersDesign a High-Precision Retrieve-and-Rerank Pipeline with ZeroEntropy Zerank-2 RerankerStability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and EditingMeet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabsDesign a Complete Multimodal RLVR Pipeline with Open-MM-RL, Vision-Language Prompting, Reward Scoring, and GRPO ExportTogether AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM ServingStep by Step Guide to Build and Compare FedAvg and FedProx Federated Learning on Non-IID CIFAR-10 with NVIDIA FLAREBest Authentication Platforms for AI Agents and MCP Servers in 2026WorkOS Releases auth.md: An Open Agent Registration Protocol Built on OAuth StandardsBuild a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and ExperimentsStepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic ComprehensionMicrosoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% on Odysseys, Up from Base GPT-5.4’s 33.5%NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta RuleTencent Open-Sources TencentDB Agent Memory: A 4-Tier Local Memory Pipeline for AI AgentsBuild a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session MemoryNous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight ModificationPerplexity Open-Sources Bumblebee: A Read-Only Supply-Chain Scanner for Developer EndpointsA Step-by-Step Coding Tutorial to Implement GBrain: The Self-Wiring Memory Layer Built by Y Combinator’s Garry Tan for AI AgentsCatch up on the Dialogues stage at Google I/O 2026.Microsoft Releases Fara1.5: A Family of Browser Computer-Use Agents (4B/9B/27B) That Outperform OpenAI Operator and Gemini 2.5 Computer Use on Online-Mind2WebBuild Recurrent-Depth Transformers with OpenMythos for MLA, GQA, Sparse MoE, and Loop-Scaled ReasoningHow CopilotKit Is Redefining the Agentic AI Stack in 2026Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context WindowCohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUsOne Model, Three Modalities: ByteDance Releases Lance for Image and Video Understanding, Generation, and EditingWhat is a Forward Deployed Engineer: The AI Role OpenAI, Anthropic, and Google Are Hiring in 2026Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant AlgorithmWe’re announcing new community investments in Missouri.100 things we announced at I/O 2026NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8BAlibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second LatencyGoogle Introduces Gemini 3.5 Flash at I/O 2026: A Faster and Cheaper Model for AI Agents and CodingUpstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?Google Launches Antigravity 2.0 at I/O 2026: A Standalone Agent-First Platform with CLI, SDK, Managed Execution, and Enterprise SupportBest Enterprise Level Agentic AI Platforms for 2026How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI APIMeet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory UtilityStochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token HorizonA Coding Implementation to Compress and Benchmark Instruction-Tuned LLMs with FP8, GPTQ, and SmoothQuant Quantization using llmcompressorVercel Labs Introduces Zero, a Systems Programming Language Designed So AI Agents Can Read, Repair, and Ship Native ProgramsA Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box ModelsNous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long ContextMeet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in ProductionNVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPUHow to Build Repository-Level Code Intelligence with Repowise Using Graph Analysis, Dead-Code Detection, Decisions, and AI ContextHow to Build an MCP Style Routed AI Agent System with Dynamic Tool Exposure Planning, Execution, and Context InjectionZyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x SpeedupBest AI Agents for Software Development Ranked: A Benchmark-Driven Look at the Current FieldSupertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression TagsHow to Build a Django-Unfold Admin Dashboard with Custom Models, Filters, Actions, and KPIsPoetiq’s Meta-System Automatically Builds a Model-Agnostic Harness That Improved Every LLM Tested on LiveCodeBench Pro Without Fine-TuningA Coding Implementation to Master GPU Computing with CuPy, Custom CUDA Kernels, Streams, Sparse Matrices, and ProfilingNous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter ModelsHow to Build a Dynamic Zero-Trust Network Simulation with Graph-Based Micro-Segmentation, Adaptive Policy Engine, and Insider Threat DetectionEnterprise AI Governance in 2026: Why the Tools Employees Use Are Ahead of the Policies That Cover ThemFastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its SizeMira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI CollaborationGoogle DeepMind Introduces an AI-Enabled Mouse Pointer Powered by Gemini That Captures Visual and Semantic Context Around the CursorBuild a Hybrid-Memory Autonomous Agent with Modular Architecture and Tool Dispatch Using OpenAIMeet AntAngelMed: A 103B-Parameter Open-Source Medical Language Model Built on a 1/32 Activation-Ratio MoE ArchitectureTilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in MuonA Coding Implementation to Portfolio Optimization with skfolio for Building Testing, Tuning, and Comparing Modern Investment StrategiesOpenAI Introduces Daybreak: A Cybersecurity Initiative That Puts Codex Security at the Center of Vulnerability Detection and Patch ValidationSakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMsA Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM ApplicationsThe new AI-powered Google Finance is expanding to Europe.Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading SystemsOpenClaw vs Hermes Agent: Why Nous Research’s Self-Improving Agent Now Leads OpenRouter’s Global RankingsNVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTXA Coding Implementation to Recover Hidden Malware IOCs with FLARE-FLOSS Beyond Classic Strings AnalysisNVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing9 Best AI Tools for Spec-Driven Development in 2026: Kiro, BMAD, GSD, and More Compare
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Training large language models on long sequences has a well-known problem: attention is expensive. The scaled dot-product attention (SDPA) at the core of every transformer scales quadratically Θ(N²) in both compute and memory with sequence length N. FlashAttention addressed this through IO-aware tiling that avoids materializing the full N×N attention matrix in high-bandwidth memory, reducing the memory footprint significantly, but the underlying Θ(N²) compute scaling remains. Researchers at Nous Research have introduced a new method called Lighthouse Attention that addresses this bottleneck specifically at pretraining time, achieving a 1.40× to 1.69× end-to-end wall-clock speedup against a cuDNN-backed SDPA baseline, with matching or lower final training loss.
The core problem with existing sparse attention methods
To understand why Lighthouse works the way it does, it helps to know what existing sparse attention methods do. Most prior work like NSA, HISA, DSA, MoBA makes the same two design decisions. First, they pool only the key and value side while leaving queries at full resolution (asymmetric compression). Second, their selection logic lives inside a custom attention kernel, which means teams can’t reuse the optimized dense-attention kernels that modern GPU tensor cores are built around.
There is also a concern specific to training that inference-only sparse methods don’t face. An inference-time sparse method is evaluated only against its dense backbone and it is at most as good as that backbone. A training-time sparse method faces a harder test: once training is done, will the resulting weights still produce a competent dense-attention model at inference? Lighthouse treats that question as its central correctness criterion.
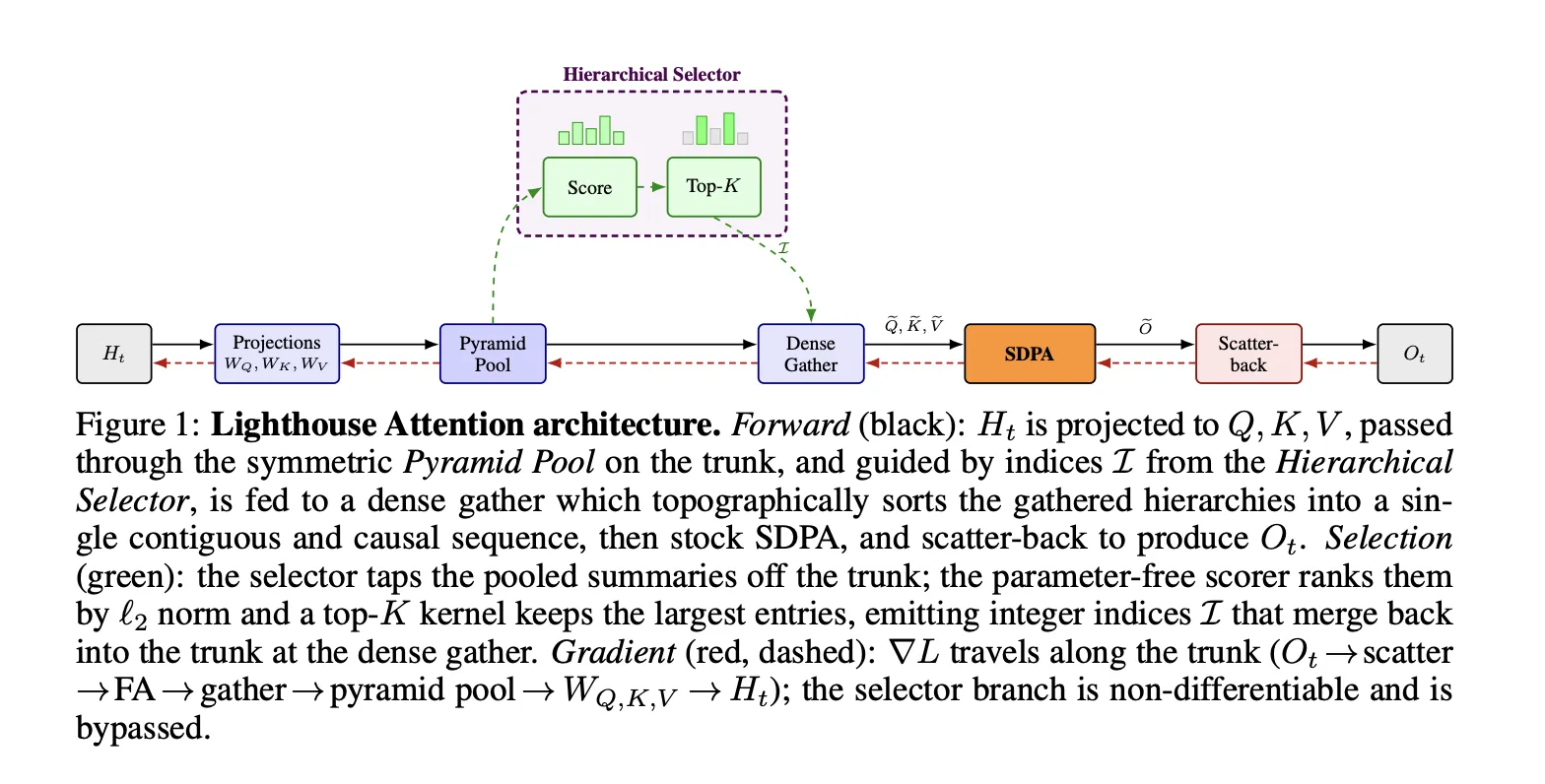
Lighthouse takes a different approach on both design decisions. It pools queries, keys, and values symmetrically across a multi-level pyramid, and it places selection entirely outside the attention kernel. After selection, the system gathers the chosen entries into a contiguous, dense sub-sequence and runs stock FlashAttention on it — the same kernel used by the dense baseline.
https://arxiv.org/pdf/2605.06554
How the four-stage pipeline works
A Lighthouse attention layer wraps around, but does not modify, scaled dot-product attention. The pipeline has four stages.
In the first stage, average pooling constructs an L-level pyramid from Q, K, and V. With pooling factor p, level ℓ of the pyramid has N/p^ℓ tokens, each summarizing p^ℓ base positions. Crucially, the same pooling applies to all three projections, producing coherent (Q^(ℓ), K^(ℓ), V^(ℓ)) triples at every level. Total pyramid construction costs Θ(N) time and memory.
In the second stage, a parameter-free scorer assigns each pyramid entry two scalar scores using per-head ℓ₂ norms: one as a query score (∥Q^(ℓ)_i∥₂) and one as a key score (∥K^(ℓ)_i∥₂). Coarser levels inherit scores from finer ones via max-pooling, so a coarse span picks up the importance of its strongest token. A fused chunked-bitonic top-K kernel then selects k entries jointly across all pyramid levels. One design detail worth noting: the coarsest pyramid level is always retained in full — it is cheap and guarantees at least one contributor at every base position; the remaining selection budget is spent on finer levels. Additionally, the chunked-bitonic design produces a stratified top-K rather than a strict global top-K: the score stream is partitioned into fixed-size chunks, each maintaining an in-register top-m buffer, so if the k globally highest-scoring entries clustered in one chunk, some would be replaced by lower-scoring entries from other chunks. The result is more balanced attention coverage across the sequence and avoids selection collapse onto a narrow span.
The top-K step is discrete and non-differentiable — no straight-through estimator, no Gumbel softmax. Selection indices carry no gradient. Gradients flow only through the gathered Q, K, V entries into WQ, WK, WV, so the projections learn to produce values that are useful when selected rather than scores that are good at selecting.
In the third stage, the selected entries are gathered into a contiguous sub-sequence of length S = N/p^(L−1) + (L−1)·p·k and passed to standard FlashAttention. At N = 1,000,000 with L = 4, p = 4, k = 4,096, S ≈ 65,000 — far smaller than N. A critical property of the gathering process is that it guarantees no “holes” or empty spaces in the assembled sub-sequence. This matters specifically because Lighthouse also compresses queries: a gap in the sequence would mean those missing tokens have no gradient path during the backward pass and could cause training instabilities. Asymmetric methods that leave queries at full resolution don’t face this problem, but Lighthouse’s symmetric design requires that the gathered sub-sequence remains fully dense.
In the fourth stage, each output entry is scattered back to the p^ℓ base positions it represents via a deterministic integer-atomic scatter kernel, with a shift of p^ℓ − 1 to preserve causality. The per-position fan-in is bounded by L regardless of k.
https://arxiv.org/pdf/2605.06554
Why symmetric pooling changes the compute
Pooling queries alongside keys and values changes the computational character of the attention call from O(N Sd) to O(S² d) at training time. Because S ≪ N at long contexts, this is what produces the latency advantage. Benchmarked on a single NVIDIA B200 at 512K context (bfloat16, B=1, H=8, head dimension 128, L=3, p=4, sparsity ≈ 1:64), Lighthouse is 21× faster on the forward pass and 17.3× faster on the combined forward+backward pass relative to cuDNN-backed SDPA.
From an asymptotic standpoint, setting L = logp(N/k) gives a gathered sub-sequence size of S = Θ(k log N), which makes the dense FlashAttention call cost Θ(k² log² N d) — polylogarithmic in N at fixed k. Combined with the linear-cost stages (pyramid construction, scoring, scatter-back), total per-layer compute is Θ(T d) at bounded k — the same asymptotic class as linear attention and SSMs — while preserving softmax attention’s recall properties on the selected sub-sequence.
Inference is a different constraint. Autoregressive decoding presents one query at a time, which violates the assumption that all queries co-occur in one forward pass. Lighthouse is a training-only method, and the symmetric pooling design cannot be used directly at inference.
The two-stage training recipe and recoverability
The experimental setup used a 530M-parameter Llama-3-style decoder (dmodel=1024, 30 layers, 8 heads, head dimension 128, FFN width 1536, byte-level tokenizer), trained on C4 at 98,304-token context with AdamW at learning rate 2×10⁻³, β1=0.9, β2=0.95, weight decay 0.1, linear warmup over 2k steps, gradient-norm clip 1, bfloat16, and FSDP. One implementation detail that matters for practitioners: of the 30 layers, layers {0, 1, 28, 29} retain dense SDPA throughout — only the other 26 layers use Lighthouse. The inner attention call within those 26 Lighthouse layers uses the same cuDNN-backed SDPA kernel as the dense baseline.
The training aproach is two-stage. Stage 1 trains with Lighthouse selection enabled for the majority of the step budget. Stage 2 resumes the Stage 1 checkpoint under dense SDPA (same optimizer state, same dataloader) for a short tail. If Stage 1 had hollowed out the model’s dense-attention capability, Stage 2 recovery would fail.
It doesn’t fail. Testing at a total budget of 16,000 steps (~50.3B tokens), three split points (10k+6k, 11k+5k, 12k+4k) were evaluated against a dense-from-scratch SDPA baseline. At each resume point the training loss spikes transiently by 1.12–1.57 nats as the model is first run through attention it was not trained against, then recovers within approximately 1,000–1,500 SDPA steps and crosses below the dense baseline. By step 16,000, all three resumed Lighthouse runs reach final losses of 0.6980–0.7102, against the dense baseline’s 0.7237, while spending 22.5h to 27.0h wall-clock compared to 37.9h for dense-SDPA-from-scratch on the same token budget.
Ablations and throughput
The full ablation grid covers scorer type, pooling factor p, number of pyramid levels L, and top-K budget k. Key findings: the projection-norm scorer is within ~0.01 of the dilated softmax-attention scorer in either direction (no uniform winner) but is roughly 9% cheaper in B200-hours, since it skips the attention pass over the pyramid entirely. Shallower pyramids (L=3) consistently outperform deeper ones (L=4, L=5) at matched budgets. Smaller k values produce lower post-resume loss within the tested range — the lowest-loss configuration across the grid is L=3, p=2, k=1536 with the dilated scorer, reaching a final loss of 0.6825 — a counter-intuitive result the research teams attribute to hierarchical selection acting as a regularizer at this token budget scale.
Stage-1 throughput across the ablation grid ranges from 84,000 to 126,000 tokens/s/GPU against approximately 46,000 for dense SDPA. The projection-norm scorer at L=3, p=4, k=1536 tops the range at 126,000 tokens/s/GPU by skipping the dilated-attention pass entirely.
Long-context retrieval
To complement the loss-based recoverability results, the research team ran a simplified Needle-in-a-Haystack (NIAH) evaluation: a single passkey digit hidden in random alphanumeric filler at depths of 0–100% across context lengths of 4K to 96K tokens, with retrieval scored as a one-token argmax over the ten digit tokens (random chance: 10%). Four Lighthouse configurations (varying k ∈ {1536, 2048} and scorer ∈ {dilated, norm} at L=3, p=4) were tested against the dense-SDPA-from-scratch baseline. Three of four Lighthouse runs match or beat the dense baseline’s mean retrieval rate of 0.72: k=2048 dilated reaches 0.76, k=1536 dilated reaches 0.73, and k=2048 norm matches the baseline at 0.72. Only k=1536 norm dips, to 0.65. A pattern emerges across the grid: larger k is the dominant axis for retrieval performance, and the norm scorer hurts retrieval more than it hurts training loss at the same k. The practical implication is that the optimal configuration depends on whether the downstream task is loss-driven or retrieval-driven.
Context parallelism scaling
For sequences beyond ~100K tokens, Lighthouse runs under context parallelism (CP). Pyramid pooling, scoring, and top-K run shard-locally on each rank with no inter-rank communication, since the coarsest pool window (e.g., 64 tokens) is orders of magnitude smaller than the shard size. The gathered sub-sequence is dense, so it participates in standard ring attention without sparse-aware collectives — something sparse-index-based methods cannot do without engineering specific to the sparse layout. Context parallelism introduces approximately 10% per-rank throughput overhead from ring rotation, but the Lighthouse vs. SDPA speedup ratio is preserved. The method scales to 1M-token training across 32 Blackwell GPUs (4 nodes, CP degree 8) with no changes to the inner attention kernel.
Marktechpost’s Visual Explainer
LH
Lighthouse Attention
Nous Research — arXiv:2605.06554
TRAINING-ONLY
01 / The Problem
Why Long-Context Training Is Expensive
Every transformer uses scaled dot-product attention (SDPA), which computes a score between every token and every other token in the sequence. As sequence length N grows, this cost scales as Θ(N²) in both compute and memory — it doubles the cost for every ~1.4× increase in context.
FlashAttention reduced this by using IO-aware tiling that avoids ever materializing the full N×N attention matrix in high-bandwidth memory, cutting memory footprint significantly. But the underlying Θ(N²) compute scaling is unchanged — the wall is still there.
Θ(N²) SDPA compute & memory scaling
1M token context frontier models target
32 B200 GPUs needed for 1M-token training
The result: teams either train at shorter contexts than they want, or spend enormous compute budgets on attention alone. Lighthouse Attention is a method that wraps around standard SDPA during pretraining to reduce this cost, then gets removed so the final model is a normal dense-attention model at inference.
02 / Prior Work
What Existing Sparse Attention Gets Wrong
Several methods already try to reduce the attention cost by attending to only a subset of tokens. But most share two design decisions that create problems for pretraining.
⚠ Problem 1: Asymmetry
Methods like NSA, HISA, InfLLM-v2 pool only keys and values but leave queries at full resolution. The hierarchy becomes a compressed memory rather than a true multi-scale representation. It also means the dense attention call stays O(N·S·d) instead of shrinking further.
⚠ Problem 2: Kernel Entanglement
Methods like NSA, DSA, HISA, MoBA embed selection logic inside a custom attention kernel. This means they cannot reuse the optimized FlashAttention kernels that GPU tensor cores are built around. Every sparse method ships its own forward and backward kernels.
The hardest problem: An inference-only sparse method is automatically as good as its dense backbone. A training-time sparse method must answer a harder question: once training is done, will the resulting weights still work as a competent dense-attention model at inference? Most methods don’t test this.
Lighthouse Attention treats this recoverability question as its central correctness criterion.
03 / The Method
Lighthouse Attention: Core Idea
Lighthouse is a selection-based hierarchical attention that wraps around, but does not modify, the attention kernel. It adds a pre-processing step that selects a small subset of tokens, runs stock FlashAttention on just that subset, and scatters the output back. At the end of training, you disable Lighthouse and keep the dense model.
Two key design differences from prior work:
✓ Queries, keys, and values are all pooled symmetrically (not just keys/values)
✓ Selection sits outside the attention kernel — FlashAttention runs on a normal dense sub-sequence
21× faster forward pass vs SDPA at 512K context
17.3× faster forward+backward at 512K context
1.69× end-to-end pretraining wall-clock speedup
The method introduces no new learnable parameters and no auxiliary losses. The scoring function is parameter-free, and the top-K selection step is deliberately non-differentiable — no straight-through estimator or Gumbel softmax.
04 / Architecture
The Four-Stage Pipeline
A Lighthouse attention layer replaces the standard SDPA call with four stages. Stages 1 and 4 are custom kernels; stages 2 and 3 are standard PyTorch operations fused by torch.compile.
1
Pyramid Pool
Average-pool Q, K, and V symmetrically into an L-level pyramid with pooling factor p. Level ℓ has N/pⁿ tokens, each summarizing pⁿ base positions. Total cost: Θ(N). Crucially, the coarsest level is always retained in full to guarantee at least one contributor per base position.
2
Score + Top-K Selection
Each pyramid entry gets two scalar scores using its per-head ℓ₂ norm: one as a query score, one as a key score. A fused chunked-bitonic top-K kernel selects k entries jointly across all pyramid levels. This step is non-differentiable — indices carry no gradient.
3
Dense Gather + FlashAttention
Selected (Q, K, V) triples are gathered into a contiguous sub-sequence of length S = N/pⁿ⁻¹ + (L−1)·p·k, then passed to stock FlashAttention. No custom sparse kernel. The gathered sequence has no holes, which is essential because queries are also compressed.
4
Scatter-Back
Each output entry is scattered back to the pⁿ base positions it represents via an integer-atomic scatter kernel. The output is fully dense. Per-position fan-in is bounded by L regardless of k.
05 / Key Design Choice
Why Symmetric Q/K/V Pooling Matters
Most prior hierarchical methods pool only K and V while leaving Q at full resolution. Lighthouse pools all three. This is not cosmetic — it changes the math of the attention call.
Method
Query side
Attention cost
NSA, HISA, InfLLM-v2
Full resolution (N)
O(N · S · d)
Lighthouse
Pooled (S)
O(S² · d)
Because S ≪ N at long contexts, O(S²·d) is dramatically cheaper than O(N·S·d). At N = 1,000,000 with L=4, p=4, k=4096, S ≈ 65,000.
The no-holes guarantee: Compressing queries means every query position must have a gradient path. Lighthouse guarantees no gaps in the gathered sub-sequence, which prevents training instabilities that would arise from tokens with missing gradients. Asymmetric methods that leave Q at full resolution don’t face this problem.
At bounded k, setting L = logᵣ(N/k) gives total per-layer compute of Θ(T·d) — the same asymptotic class as linear attention and SSMs, but with softmax attention’s recall properties on the selected sub-sequence.
06 / Gradient Flow
Non-Differentiable Selection, Differentiable Training
The top-K step is discrete. Lighthouse deliberately does not approximate it with a straight-through estimator or Gumbel softmax. This is a conscious design choice.
What does NOT get gradients
The selection indices and the scoring function. The ℓ₂ norm scorer is never trained — it has no parameters and receives no gradient signal.
What DOES get gradients
Gradients flow through scatter-back → FlashAttention → gather into the gathered Q̃, K̃, Ṽ and on into W_Q, W_K, W_V.
The result: the projection matrices learn to produce values that are useful when selected, not scores that are good at selecting. This avoids the optimization problems — scorer collapse, scorer–attention misalignment, auxiliary loss tuning — that learnable selectors in NSA and DSA are prone to.
Complexity comparison across attention families (per-layer compute at bounded k):
The central claim of Lighthouse is that sparse training does not break the model’s ability to use dense attention at inference. The two-stage recipe is how this is validated.
1
Stage 1 — Lighthouse pretraining
Train for the majority of the step budget with Lighthouse selection active. This is the fast stage: ~2× higher throughput than dense SDPA.
2
Stage 2 — Dense SDPA resumption
Resume the Stage 1 checkpoint under standard dense SDPA with the same optimizer state and dataloader. The loss spikes transiently by 1.12–1.57 nats, then recovers within ~1,000–1,500 SDPA steps and crosses below the dense baseline.
Tested at 16,000 total steps (~50.3B tokens) on a 530M Llama-3-style model (dmodel=1024, 30 layers, H=8, head dim 128, FFN 1536, byte-level tokenizer, C4 dataset, 98,304-token context) across three split points:
Split
B200–Hrs
Tok/s (k)
Final Loss
Dense SDPA baseline
303.2
45.6
0.7237
LH 12k + SDPA 4k
214.7
74.7
0.7102
LH 11k + SDPA 5k
219.6
75.4
0.7001
LH 10k + SDPA 6k
228.0
75.0
0.6980
All three Lighthouse runs beat the dense baseline at matched token budgets.
08 / Implementation Detail
Not All Layers Use Lighthouse
An important detail for practitioners: in the 30-layer experimental model, layers {0, 1, 28, 29} retain dense SDPA throughout. Only the remaining 26 layers use Lighthouse. The inner attention call within those Lighthouse layers uses the same cuDNN-backed SDPA kernel as the dense baseline.
This means Lighthouse is a partial replacement, not a full model-wide substitution. The first and last layers keeping dense attention is a practical stabilization choice — these boundary layers often carry disproportionate importance for model behavior.
Optimizer setup: AdamW, lr 2×10⁻³, β₁=0.9, β₂=0.95, weight decay 0.1, linear warmup over 2k steps, gradient-norm clip 1, bfloat16, FSDP only.
Chunked-bitonic top-K: The kernel produces a stratified top-K, not a strict global top-K. Score stream is partitioned into fixed-size chunks; each chunk maintains an in-register buffer. If the globally highest-scoring entries clustered in one chunk, some are replaced by lower-scoring entries from other chunks — guaranteeing every region of the sequence contributes tokens and preventing attention from collapsing onto a narrow span.
S = N / p^(L-1) + (L-1) * p * k
# Example: N=1M, L=4, p=4, k=4096
# S = 1,000,000/64 + 3*4*4096
# S = 15,625 + 49,152 ≈ 65,000 (vs 1,000,000 for full attention)
09 / Ablations
What the Hyperparameter Sweep Shows
The full ablation grid varied scorer type, pooling factor p, pyramid levels L, and top-K budget k. All configurations used the 10k+6k split at 98K context.
Config
Scorer
B200–Hrs
Tok/s (k)
Final Loss
SDPA baseline
—
303.2
45.6
0.7237
L=3, p=2, k=1536
Dilated
203.9
93.9
0.6825
L=3, p=4, k=1536
Dilated
197.2
99.5
0.6881
L=3, p=4, k=1536
Norm
179.6
126.0
0.6946
L=3, p=2, k=4096
Dilated
215.7
83.5
0.6951
Key findings from the sweep:
Smaller k → better loss (counter-intuitive) Shallower L=3 beats L=4, L=5 Norm scorer: 9% cheaper, similar quality Every config beats dense baseline
The counter-intuitive finding on k: loss decreases monotonically as k shrinks from 4,096 to 1,536. The authors attribute this to hierarchical selection acting as a regularizer at the 50.3B-token budget. Whether this reverses at larger budgets is left to future work.
10 / Retrieval Evaluation
Needle-in-a-Haystack Results
Beyond training loss, the paper evaluates long-context retrieval using a simplified Needle-in-a-Haystack (NIAH) test: a single passkey digit hidden in random alphanumeric filler at depths of 0–100% across context lengths of 4K–96K tokens. Retrieval is scored as a one-token argmax over the ten digit tokens. Random chance is 10%.
Configuration
Mean Retrieval Rate
vs Baseline
Dense SDPA baseline
0.72
—
k=2048, Dilated scorer
0.76
+0.04
k=1536, Dilated scorer
0.73
+0.01
k=2048, Norm scorer
0.72
Matches
k=1536, Norm scorer
0.65
−0.07
Three of four Lighthouse configurations match or beat the dense-from-scratch baseline on retrieval. The norm scorer hurts retrieval more than it hurts training loss at the same k. The practical implication: if your downstream task is retrieval-heavy, use a larger k and the dilated scorer. If optimizing for loss and throughput, the norm scorer with k=1536 is the better trade-off.
11 / Scaling
Context Parallelism at 1M Tokens
For sequences beyond ~100K tokens, the 530M model OOMs on a single B200 regardless of attention method (activations + gradients + optimizer state). Lighthouse extends to multi-GPU context parallelism (CP) cleanly.
1
Shard-local pre-attention
Each rank holds a contiguous slice of the sequence. Pyramid pooling, scoring, and top-K all run shard-locally. The coarsest pool window (e.g., 64 tokens) is far smaller than the shard size (N/W ≈ 128K at N=1M, W=8), so no inter-rank communication is needed at this stage.
2
Standard ring attention
The gathered sub-sequence is dense, so it participates in standard ring attention with no sparse-aware collectives. KV shards rotate through the ring as in a fully dense long-context run. Sparse-index-based methods cannot do this — ring rotation requires a contiguous tensor, which their sparse outputs are not.
~10% ring-rotation overhead in CP vs single-device
1M token training context achieved
4×8 nodes × GPUs, CP degree 8
The Lighthouse vs. SDPA speedup ratio is fully preserved under matched CP geometry, carrying the advantage cleanly into the 1M-token regime.
12 / Limitations & Resources
Limitations and Open Directions
Key limitation: Symmetric Q/K/V pooling presumes all queries co-occur in one forward pass. Autoregressive decoding presents one query at a time — this violates that assumption. Lighthouse is a training-only method and relies on the dense-SDPA resumption to produce an inference-ready model. The gathered sub-sequence cost is Θ(S²·d): sub-quadratic in N at fixed k, but not strictly linear. Regimes where k must scale with N remain uncharacterized.
Nous Research’s Lighthouse Attention pools Q, K, and V symmetrically across a multi-level pyramid — unlike NSA and HISA which only pool K and V — cutting the attention call from O(N S d) to O(S² d) and making the expensive step stock FlashAttention on a small dense sub-sequence.
It’s a training-only method: a brief dense-SDPA resumption at the end converts the checkpoint into a normal full-attention model that matches or beats dense-from-scratch at the same token budget (final loss 0.6980–0.7102 vs. 0.7237 baseline, 16k steps, ~50.3B tokens).
At 512K context on a single B200, Lighthouse is 21× faster on the forward pass and 17.3× faster on forward+backward vs. cuDNN SDPA — translating to a 1.40×–1.69× end-to-end pretraining wall-clock speedup.
The top-K selection step is deliberately non-differentiable — no straight-through estimator, no Gumbel softmax — so projection matrices learn to produce values that are useful when selected, not to game a learnable scorer.
Scales to 1M-token training across 32 Blackwell GPUs (4 nodes, CP degree 8) under context parallelism with no changes to the inner attention kernel, because the gathered sub-sequence is dense and participates in standard ring attention.