admin
- 2 6 月, 2026
- 0 Comments
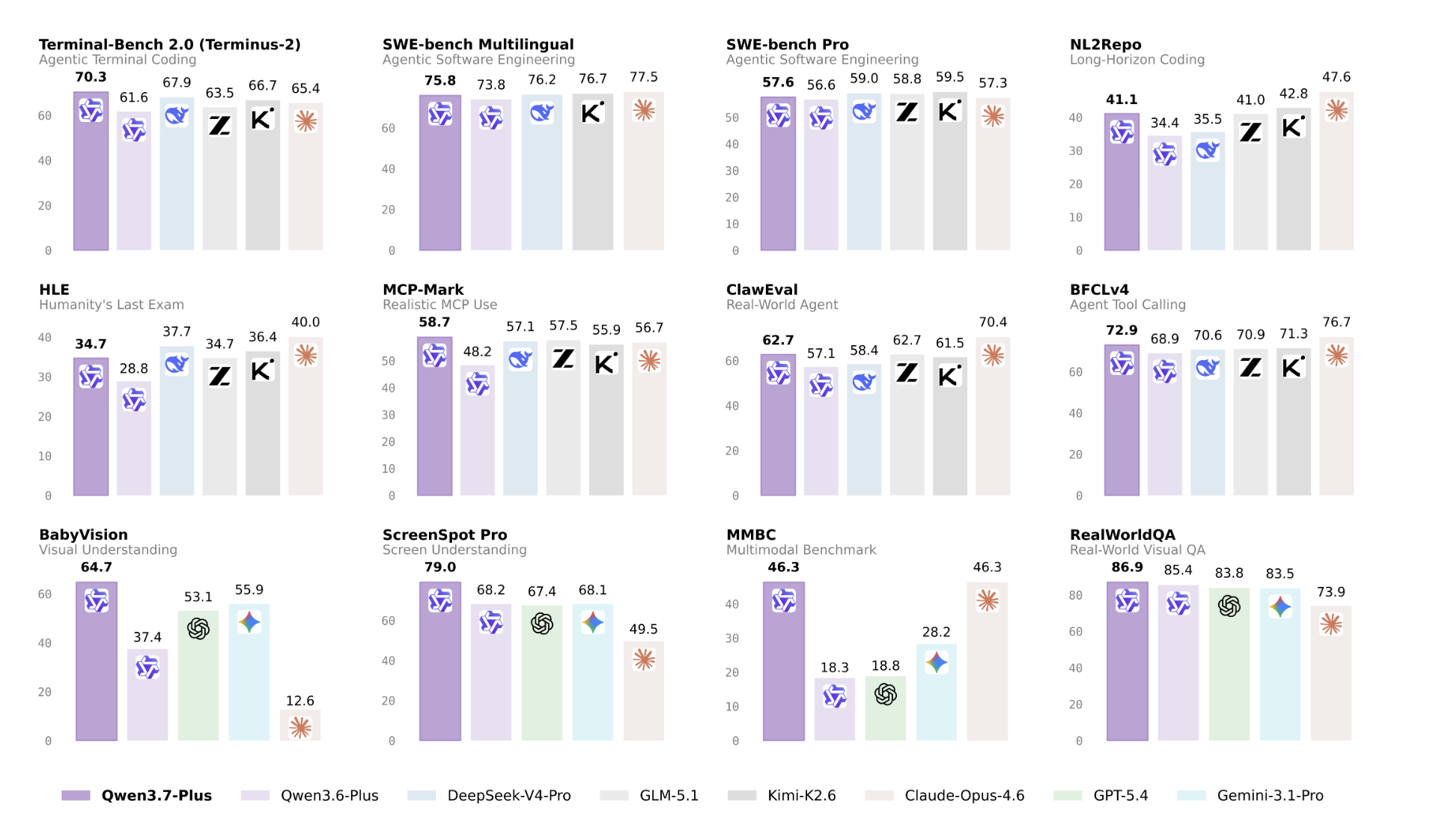
Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian Platform
Alibaba’s Qwen team has releas…
Alibaba’s Qwen team has releas…
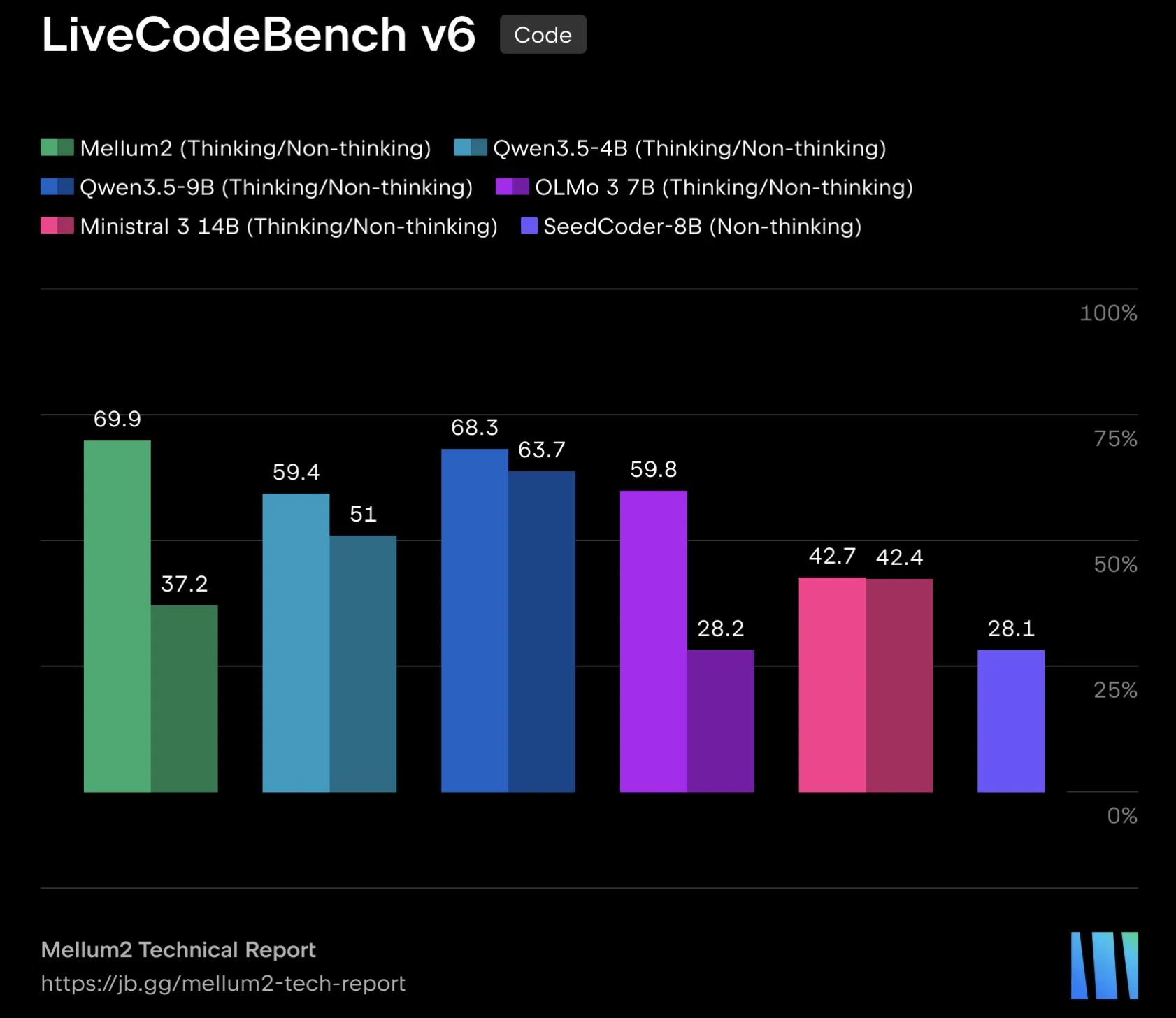
JetBrains released Mellum2, op…

In this tutorial, we work thro…
MiniMax officially released Mi…
Hermes Agent already remembers…
Learn how Googlers used AI to …
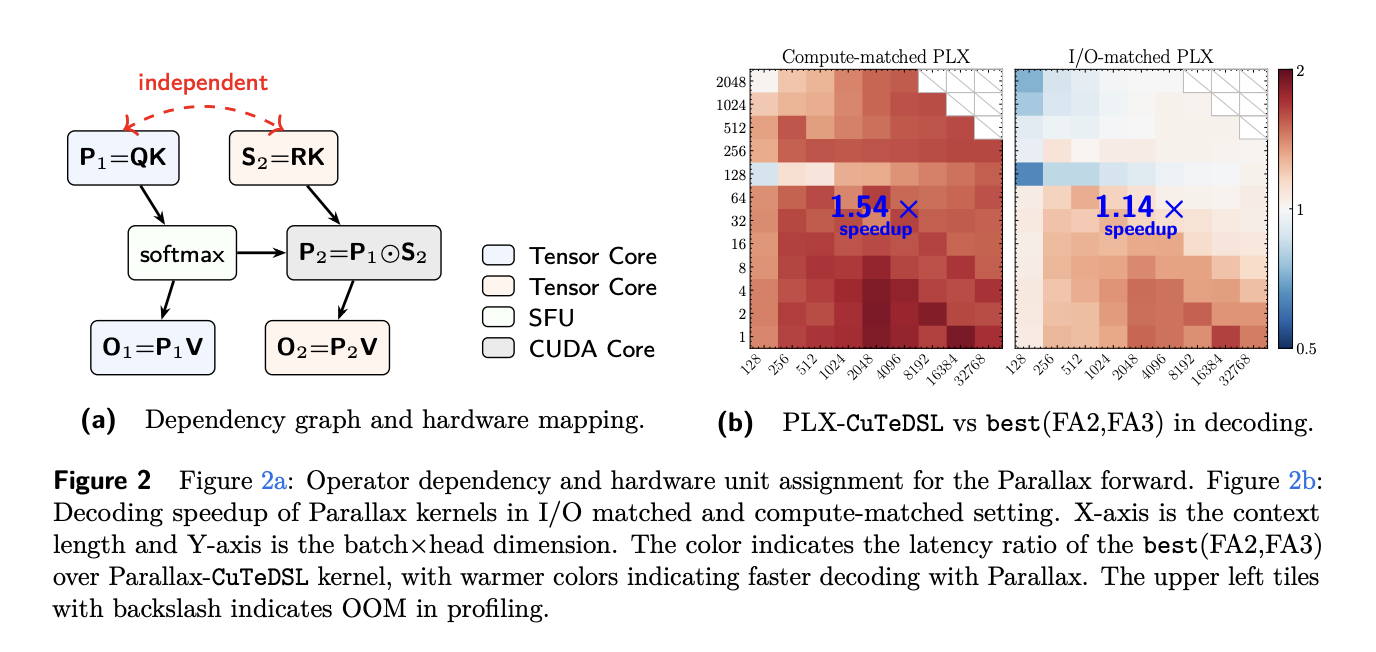
The Transformer’s attention me…
In this tutorial, we build a g…