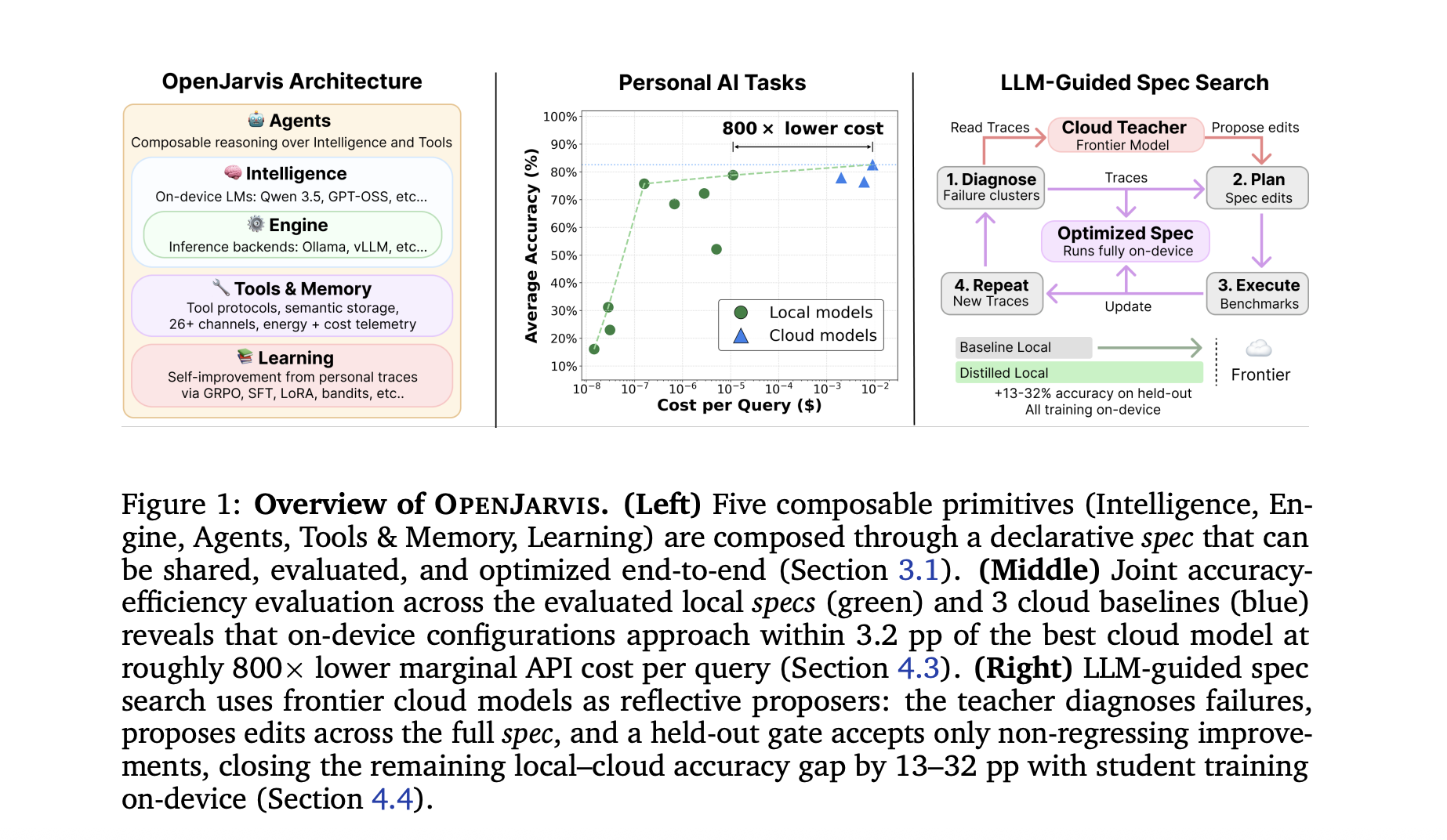
Researchers at Stanford University and Lambda Labs, have published the research paper for OpenJarvis, an open-source framework that runs inference, agents, memory, and learning entirely on-device.
The open-weight models configured through OpenJarvis land within 3.2 percentage points of the best cloud model on average, at roughly 800× lower marginal API cost per query and roughly 4× lower latency under the research’s benchmark protocol. This research work builds on the research team’s earlier Intelligence Per Watt study, which reported that local models already handle 88.7% of single-turn chat and reasoning queries at interactive latency, with intelligence efficiency improving 5.3× from 2023 to 2025.
Model Overview & Access
OpenJarvis is not a single model. It is a framework that composes any supported model with a configurable agent stack, evaluated across 11 local models from four families.
| Property | Value |
|---|---|
| License | Apache 2.0 |
| Framework release | March 12, 2026 |
| Paper | arXiv:2605.17172 (posted May 16, 2026) |
| Repository | github.com/open-jarvis/OpenJarvis |
| Stars / forks | ~5.4k / ~1.2k (June 2026) |
| Languages | Python (~83%), Rust (~9%), TypeScript (~7%) |
| Evaluated models | 11 local models across 4 families: Qwen3.5, Gemma4, Nemotron, Granite |
| Cloud baselines | Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro |
| Supported engines | Ollama, vLLM, SGLang, llama.cpp, Apple Foundation Models, Exo (among others) |
| Context window | Model-dependent |
| Installation | Single command; ~3 minutes on broadband |
| Hardware | Tested on 7 platforms, from Mac Mini M4 to NVIDIA DGX Spark |
Architecture: Five Primitives and a Spec
OpenJarvis decomposes a personal AI system into five typed primitives, composed through a single declarative configuration object called a spec.
- Intelligence — the model, weights, generation parameters, and quantization format.
- Engine — the inference runtime (Ollama, vLLM, SGLang, etc.), batching, KV-cache settings, and hardware path.
- Agents — the reasoning loop (ReAct or CodeAct), system prompts, tool-use policy, and turn limits.
- Tools & Memory — external interfaces, retrieval backends, 25+ data connectors, and 32+ messaging channels, with native MCP support and interchangeable memory backends.
- Learning — the optimizer that updates the spec from traces. This slot accepts LoRA, DSPy, GEPA, or LLM-guided spec search.
Each primitive is independently swappable, and a spec serializes all five into a TOML file. Two specs can share the same agent and tool configuration and differ only in model and engine, so the same behavior runs on a Mac Mini and a workstation without rewriting prompts.
LLM-guided spec search is the second contribution. It is a local–cloud collaboration: a frontier cloud model acts as a teacher at search time, reading traces, diagnosing failure clusters, and proposing edits across Intelligence, Engine, Agents, and Tools & Memory. An edit is accepted only if it improves the target failure cluster without causing meaningful regressions elsewhere — the research team calls this the gate (default tolerance 1%). The optimized spec then runs entirely on-device at inference time, with zero cloud calls. The teacher is used only at search time; at 100 queries per day, the amortized teacher cost falls below $0.001 per query within six months.
Prior work (GEPA, DSPy, LoRA) optimizes one primitive at a time, and prompt optimizers alone recover only about 5 pp of the cloud–local gap. LLM-guided spec search recovers 13–32 pp because it edits across primitives jointly, at 7–11× lower optimization cost than single-primitive baselines. The four-primitive move space contributes 5.5–16.5 pp, and the LLM proposer adds about 10 pp on average over an evolutionary search at the same move space.

Capabilities & Performance
OpenJarvis was evaluated across 8 benchmarks spanning 508 tasks: tool calling (ToolCall-15), agentic workflows (PinchBench), coding (LiveCodeBench), customer service (τ-Bench V2, τ²-Bench Telecom), general assistance (GAIA), and deep research (LiveResearchBench, DeepResearchBench).
The swap test: Replacing the intended cloud model with Qwen3.5-9B in existing frameworks (OpenClaw, Hermes Agent) drops accuracy by 25–39 pp. With the same model under an OpenJarvis spec, the residual drop shrinks to 5.6–16.5 pp — recovering 56–77% of the portability loss.
The accuracy frontier: The best single local model, Qwen3.5-122B, reaches 80.3% average accuracy versus Claude Opus 4.6 at 83.5% — a 3.2 pp gap. Local specs match or exceed cloud on 4 of 8 benchmarks: ToolCall-15, PinchBench, LiveCodeBench, and τ-Bench V2.
Cost and latency: Local configurations form the accuracy–efficiency frontier. Qwen3.5-122B delivers its 80.3% at roughly a thousandth of a cent per query, versus $0.009 per query for Claude Opus 4.6 — an approximately 800× marginal API-cost advantage. End-to-end latency drops by roughly 4× on the agentic workloads, though the paper notes single-shot prompts can favor cloud serving.
Search gains: LLM-guided spec search improves the Qwen3.5-9B student to 100% on PinchBench, 83% on LiveCodeBench, and 91% on LiveResearchBench. Across the full eight-benchmark suite, average gains per student model range from 13.1 to 31.5 pp. The authors report that these gains survive their robustness checks (reward-weight variants, search-seed variance, and random restarts).
How to Use it
Installation is one command. On macOS, Linux, or WSL2:
curl -fsSL https://open-jarvis.github.io/OpenJarvis/install.sh | bashWindows users run an equivalent PowerShell script (irm … | iex). The installer provisions uv, a Python virtual environment, Ollama, and a starter model in about three minutes on broadband. A desktop GUI ships as a .dmg, .exe, .deb, .rpm, or .AppImage from the releases page.
After install, jarvis starts a chat session. Starter presets cover common workflows:
jarvis init --preset morning-digest-mac # daily briefing with TTS
jarvis init --preset deep-research # multi-hop research with citations
jarvis init --preset code-assistant # agent with code execution and shell access
jarvis init --preset scheduled-monitor # stateful agent on a scheduleThe framework ships with eight built-in agents across three execution modes — on-demand, scheduled, and continuous. It connects to 25+ data sources (Gmail, Calendar, iMessage, Notion, Obsidian, Slack, GitHub, and others) and exposes agents over 32+ messaging channels (WhatsApp, Telegram, Discord, iMessage, Signal, and others).
Skills can be imported from external catalogs — about 150 from Hermes Agent and about 13,700 community skills from OpenClaw — all following the agentskills.io specification. A jarvis optimize skills --policy dspy command refines them from local trace history.
Marktechpost’s Visual Explainer
01 / 07
Key Takeaways
- OpenJarvis runs inference, agents, memory, and learning fully on-device, landing within 3.2 pp of the best cloud model at ~800× lower marginal API cost and ~4× lower latency.
- A typed “spec” decomposes the stack into five swappable primitives — Intelligence, Engine, Agents, Tools & Memory, and Learning — serialized to portable TOML.
- LLM-guided spec search uses a frontier cloud model as a search-time teacher to recover 13–32 pp of the cloud–local gap at 7–11× lower optimization cost, then runs locally with zero cloud calls.
- Local specs match or exceed cloud on 4 of 8 benchmarks (ToolCall-15, PinchBench, LiveCodeBench, τ-Bench V2); the remaining gap concentrates on reasoning- and research-heavy tasks.
Check out the Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Meet OpenJarvis: A Local-First Framework for On-Device Personal AI Agents with Tools, Memory, and Learning appeared first on MarkTechPost.